こんにちは。沼津に引っ越す予定の浜松体育です。
前回もRAG関係の記事を書きましたが、こういったAI系の技術を扱うとき、例えば自社内のデータが流出しないかどうか気にする必要があるなどして、実務で採用するためにはある種のハードルがあると思います。本稿はそうしたハードルを比較的下げつつ、任意のデータを対象にRAGによる質問応答を行う試みについて記載しました。
今回はローカルLLMを構築し、Notionに入力した情報を対象にRAGによる質問応答を試みます。
今回できるようになったこと
使ったNotionのページ


筆者は個人的に、『蓮ノ空女学院スクールアイドルクラブ』というアニメのセリフを文字起こしにして、それをデータとしてNotionにためています。
このコンテンツにはかなりの情報量があって、熱狂的なオタクでも「あれって何話の出来事だっけ?」といった困り事が起こりがちなので、それを解決するためにこうしてNotionに情報をためています。
※ 念のためのおことわりとして、無料で公開されているコンテンツのデータのみをNotionにためているため、個人利用の範疇で問題のない運用だと考えています。
作ったWebアプリの様子
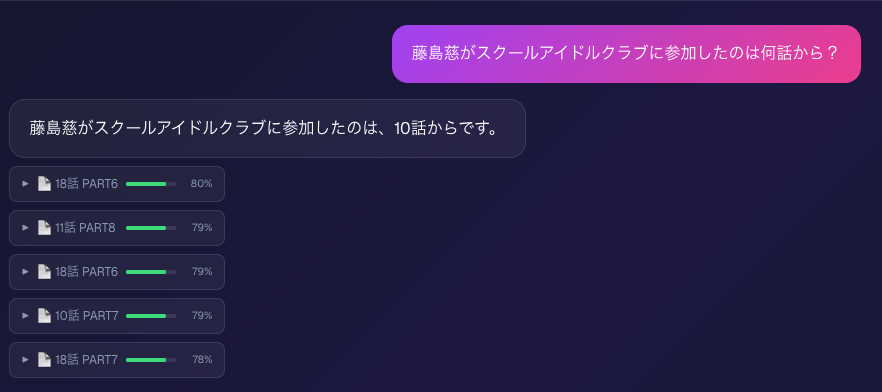
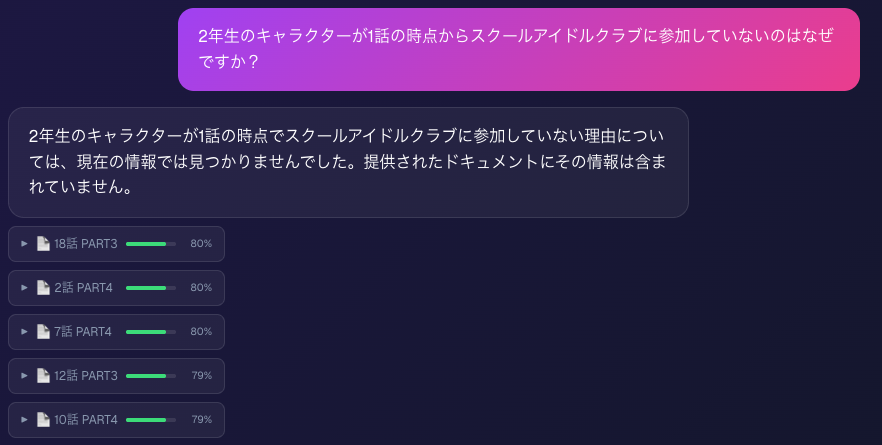
今回対象にしたデータがアニメのセリフの文字起こしだったため、いくつかの困難が生じました。というのも、アニメのセリフだけではアニメの動きを捉えることができないため、データとしては思いのほか情報が不足していたのです。このため、「良い感じに」検索しようとすると、セリフとして表出した情報を用いる必要が生じてしまいました。
また、RAGという技術の特性上、「データにないことを憶測で生成して回答しない」ように調整を行なっているため、データを分析して回答をさせるといったことは困難でした。
余談として、『蓮ノ空女学院スクールアイドルクラブ』では、「藤島慈」というキャラクターが上級生にも関わらず途中加入(「途中参加」と質問しましたが)するシナリオがあります。このため、「あれってNotionのどこに書いてあったっけ?」という検索のシミュレーションとして適切だと考え、今回作成したアプリでもそれを試すように実行をしました。
結果として慈が途中参加した「話数」については正しく表示できたのですが、それがどの「PART」だったのかは不正確でした。これは「途中参加」したという表現がセリフからは読み取りづらかったことが原因だと考えています。実務上はデータがこのようにあいまいということは少ないとは思うので、この点は特有の挙動だと感じました。
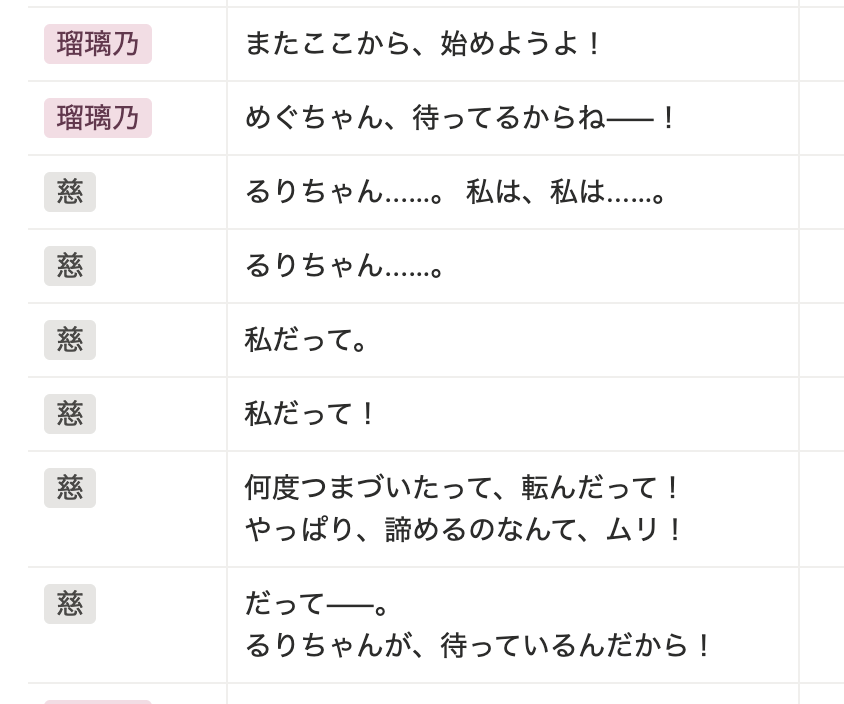

(↑「あ……。」の直前に暗転していて、PTSDを抱えた慈が衣装を着てライブに乗り込んでくるシーン。こうした文面を見て「途中参加」したと理解できるのはアニメの動きを見たことのある人ぐらい。)
GitHubで公開しています
https://github.com/kke-me/local-rag-for-notion/tree/main
ほぼ全てを生成AIによるコーディングで実装しているためかなり荒削りですが、今回作成したWebアプリについては上記URLでコードを公開しています。
当該Notionのデータは含まれていないため、任意のNotionのデータを用意して試してみてください。
NotionにRAGを使いたかった動機
Notionは痒いところに手が届かない
Notionはまず検索機能が微妙で、これによって「あれってどのページに書いてあったっけ…?」が発生してしまいます。Notion単体で膨大なデータを取り扱ってしまうと、データが埋もれがちです。
また、Notionというサービスは設計上、仕組みが素朴だと考えています。Notionが用意している特段のルールが無くページをあちこちに配置することができてしまうため、ページの階層構造を適切にしたり、その案内のためのページを作成するといった工夫が必要です。
このため社内のデータをNotionにためていくことで、例えば新入社員にとってはあまり優しくないデータベースと化してしまいがちです。
RAGならどうか
RAGというとGoogleが提供しているNotebookLMのように、チャットベースで任意の情報を検索することができる体験が一般的だと思います。
使用感としてはそのような簡単なものを目指し、かつ、Notionの「検索機能が微妙」という欠点を潰していきたい!というのがNotionにRAGを使いたかった動機です。
技術的な説明
技術的なフロー

(図が一部切れてしまっていて申し訳ないのですが)、上図が今回行なっている技術的なフローです。
この「外部サービス」というのは取得可能なら何でも構わなくて、例えばGoogleのスプレッドシートのようなものでも良いかもしれません。今回はNotionを対象にしたので、このデータをNotion APIを使って取得し、AIに取り込ませて処理しています。
今回作ったWebアプリには、外部サービスから取り出したデータをあらかじめ用意しておきます。これをいざ使おうというときには、Webアプリを使ってチャットするだけで外部サービスのデータを検索できるというわけです。
外部サービスのデータが書き換わった際にはそのデータを再度取り込む必要があります。この点は最適化する必要があり、例えば差分検知の仕組みを整えておき、外部データのデータが書き換わった部分のみを取り込むことにすることでデータの取り込みを最小限にできます。

より細かく表すと上図のようになるのですが、この仕組みについてはかなり長い説明が必要になってしまうため、本稿では詳細を割愛します。
技術スタックについて
上図が技術スタックになります。Node.jsの環境で構築しています。
LLMは「qwen2.5-7b-instruct」というモデルを利用しました。
データを流出させないAI活用について
外部サービスにデータを送信しない
AI活用においてデータを流出させないというのは、つまるところ「外部サービスにデータを送信しない」ということに尽きると考えます(ここではこのことを「データを安全に使う」と言い換えます)。
例えば、一般的にAIサービスを会社で使おうとすると、特に無料プランでは「データを送信」することになってしまったりして、「うーん、コンプライアンス的に使えないな…」といった意思決定を下すことになってしまうと思います。
しかしそれが一般的な意思決定であり、データを安全に使うことはAIサービスを使うことよりも優先されがちです。
ローカルLLMを使う
ローカルLLMとは、インターネットを介さないLLM(つまりAIのこと)のことを指します。
ここでは、インターネットに接続されていないマシン上にLLMを構築し、これにアクセスしてデータを取り扱います。つまり、これによるとデータを安全に使うことができるというわけです。
実務上この説明をするために相当の準備が必要になると思うのですが、これについても割愛したいと思います。かなり長い説明が必要になってしまうためです…
反省・展望
強いマシン・強いモデルが必要

やはり「イマイチだな…」という回答が返ることがあり、まだまだ調整が必要だと感じました。
例えば上図なのですが、キャラクターの名前に対して「さん」とか「センパイ」といった名称が付属してしまっています。
どういうことかというと、アニメの字幕上、花帆が上級生を呼ぶ際には「センパイ」というカタカナの表示に必ずなっていたり、梢が下級生を呼ぶ際には「さん」が(ほぼ)必ず付属したりする、キャラクターの発言のクセという文字情報を拾ってしまっていて、それが一般的な情報として判定されているのです(このアニメにはこのような厳格な仕様があって、さやかや瑠璃乃なら、上級生を「先輩」と呼びます)。
これは質問した通りに「花帆」だったり「梢」だったり、必ず固有名詞で返してほしいです(そうしたプロンプトを仕込んでいるはずなのに…)。
結局のところ、マシンやモデルが強いことが前提になってしまうと考えています。仕組み自体は良い線をとらえていると思うのですが、これをチューニングして良い出力を目指すより、そもそも強いマシンで強いモデルを動かす方が早いと考えています。
今回はローカルマシンとしてM3チップを搭載したRAMが16GBのMacBook Proを使用しました。このマシンでは現実的に使用に耐えるモデルが「qwen2.5-7b-instruct」だったためこのモデルを使用しているにすぎず、使えるのならより強いモデルを使うことで、Webアプリの水準を向上させるために試行錯誤をしたかったです。
RAGについての理解がもう少し必要
今回RAGを扱うにあたっては「Embeddingモデル」といって、今回の「qwen2.5-7b-instruct」とは別に言語モデルを利用しています(Ruri-v3を採用)。これはデータを検索しやすくするためのモデルです。
ユーザーの入力と関連したドキュメントを探すためには、ユーザーの入力と、データ上の文字情報の類似度を評価し、関連しているかどうかを判定する必要があります。このためにデータをあらかじめLLMにとって検索しやすいように変換することができるモデルが、Embeddingモデルです。
これを適切に利用するなどしてRAGの使い心地を調整していくのですが、そのためにはそもそもこうした前提知識が無数に必要で、Webアプリの構築以上にまずは理解がかなり必要だと感じました。
Notionという媒体の難しさ
先述した「痒いところに手が届かない」という難しさのほかに、Notion APIの難しさなどが課題として感じられました。
Notionに素朴なテキストだけが入力されていればいいのですが、Notionにはデータベースやリンクといった特有の仕様があり、これをNotion APIを駆使して全て取得する必要があります。
さらに、Notion APIのリクエスト上限に抵触しないようにデータを集める必要などがあり、今回Webアプリをまず動作させるためだけにも、この調整がかなり必要でした。
おわりに
弊社における私の所属では、Notionにさまざまなナレッジを集約するようになってきています。
Notionは素朴で便利なのですが、他方で、「あれってどのページに書いてあったっけ…?」という体験にまつわる課題感が常にあります。これは絶対に解決したい課題だと考えていて、解決できれば、例えば業務委託で参加してくださるメンバーへの情報共有がずっとスムーズになると考えています。
実用水準に仕上げるまでこの取り組みを続けたいと考えているので、引き続き開発を続けていきたいです。
関連記事
-
第1回 Visual C++で作成したDLL内のクラスをC#で利用する方法
こんにちは、ILCです。 Visual C++ (以下 VC++)で作成されたDynamic...
公開日:2024.01.19 更新日:2024.01.19
tag : Windows
-
-
-
【新機能探訪】Android 13から導入された『アプリごとの言語設定』
こんにちは、KNSKです。よろしくお願いします。 今回は Android13の新機能である『...
公開日:2022.12.09 更新日:2022.12.09
tag : スマートデバイス
-
第1回 ラズパイを使用したBLE通信 ~ ディスプレイ、キーボード、マウスを接続しないで設定 前編 ~
こんにちは、GTです。よろしくお願いします。 最近業務でラズパイのBluetooth機能を使...
公開日:2021.12.24 更新日:2021.12.24
tag : Bluetooth Raspberry Pi
-
こんにちは。WwWです。 システム系の開発をしていると様々な問題が起こります。 そこで今回は...
公開日:2023.04.28 更新日:2023.04.28





